Source Documentation
blocks.py
- class flows_sdk.blocks.Block(identifier, reference_name=None, input=None, title=None, description=None, error_handling=None, compatibility_spec=None)
Bases:
objectBase structure representing an executable within a Hyperscience deployment. Available blocks depend on the version of the underlying Hyperscience platform, but additional blocks may have also been manually installed. Check out IDP Library for example blocks used for the Document Processing flow that comes with V32.
- Parameters:
reference_name (
Optional[str]) – unique identifier on a per-Flow basis, used to identify the concrete block within a Flow (e.g., in order to reference the outputs of a concrete block)identifier (
str) – block implementation that will be used at runtime (e.g., MACHINE_CLASSIFICATION). Multiple blocks with same identifier can be present in a Flow.input (
Optional[Dict[str,Any]]) –key-value dict being passed during execution of the Block. Can both have static values or various dynamic values (e.g., output from a previously executed block, see
flows_sdk.blocks.Block.output()). Most blocks have mandatory inputs, depending on their identifier. For example:{ 'a': 42, 'b': 'foo', 'c': some_previous_block.output(), 'd': another_previous_block.output('nested.path') }
title (
Optional[str]) – UI-visible title of the block.description (
Optional[str]) – Description of the block. Both useful for documentation purpose and visible to users in the Flow studio.error_handling (
Optional[ErrorHandling]) – The error handling policy that will be applied to this block.compatibility_spec (
Optional[CompatibilitySpec]) – What flows or blocks can this block be changed with on the UI. “filter_roles” param takes a list of strings that represent roles. “filter_schema” param is a JSON schema, that allows for more intricate filtering. “label” represents the UI label in FlowStudio
- output(key=None)
Used to reference the output of a block that has already been executed. For example, if we have a Flow with two blocks, the second can reference the output of the first as part of its inputs.
- Parameters:
key (Optional[str]) – When not provided, the entire output of the referenced block will be passed along. When provided, will pass a concrete key from the output (e.g. for an output like
{"a": 42}, callingoutput()will pass it as a dictionary, while callingoutput("a")will pass42.)- Returns:
a string-formatted reference that will be unpacked to a value during runtime.
- Return type:
str
For example:
a = Block(...) b = Block( ..., input = { 'foo': a.output('bar') } )
- class flows_sdk.blocks.BaseCodeBlock(code, identifier, reference_name=None, input=None, title=None, description=None)
Bases:
Block- output(key=None)
CodeBlock nests the actual result returned from the provided function under the ‘result’ key. This method overrides the default output, removing the need to always prepend ‘result’ when calling CodeBlock.output(…)
- Parameters:
key (
Optional[str]) –Optionally provide a key to directly get a nested property. When not provided, the entire ‘result’ will be returned.
For example, we have:
{ "result": { "a": { "b": 42 } } }
skipping the key
output()` will return ``{"a": {"b": 42}}calling with
output("a")will result in{"b": 42}calling with
output("a.b")will return42
- Return type:
str- Returns:
the value under the provided key
- class flows_sdk.blocks.PythonBlock(code, reference_name=None, code_input=None, input=None, title=None, description=None, python_version=None)
Bases:
BaseCodeBlockPython Blocks are a special type of block that can run custom Python code on the Hyperscience Platform. Code will be serialized, then, as part of a flow run, executed on an isolated environment. By default, users can only utilize packages that are part of the Python Standard Library. To access third-party Python packages, users need to follow these instructions to have them installed on the Hyperscience Platform.
Lambda functions are executed in the context of the execution engine itself (less overhead, but cannot be scaled) Code functions are executed in a dedicated container (more overhead, can scale horizontally)
The PythonBlock can be compiled to blocks that run on different Python versions. There are several ways to modify the behavior.
By default, the Python version of the PythonBlock will be set based on the Python version of the current Python virtual environment. For example, if the current virtual environment uses Python 3.11, the PythonBlock will be compiled to a Python 3.11 block. If the version is not supported, it would default to Python 3.9 block.
To override the default behavior controlled by the virtual environment, an environment variable - HS_PYTHON_CODE_BLOCK_PYTHON_VERSION - can be set. All blocks would be compiled to use the Python version dictated by that variable. It can be set to 3.9, 3.11 or 3.12.
To enable more fine-grained control over the Python version of the block, python_version parameter can be explicitly set to each PythonBlock instance using one of the available values in the
flows_sdk.blocks.PythonBlock.SupportedPythonBlockPythonVersionenum.Python Block version modifier precedence
virtual env version < HS_PYTHON_CODE_BLOCK_PYTHON_VERSION env var < specific python_version argument to PythonBlock
Python version examples:
Default behaviour, given a virtual environment based off Python 3.9:
PythonBlock( reference_name='ref_name', code=lambda x, y: x + y, code_input={'x': 0, 'y': 1} ) produces: { "identifier": "PYTHON_CODE", "reference_name": "ref_name", "input": {"data": {"x": 0, "y": 1}, "code": "lambda x, y: x + y"} }
Default behaviour, given a virtual environment based off Python 3.11:
PythonBlock( reference_name='ref_name', code=lambda x, y: x + y, code_input={'x': 0, 'y': 1} ) produces: { "identifier": "PYTHON_3_11_CODE", "reference_name": "ref_name", "input": {"data": {"x": 0, "y": 1}, "code": "lambda x, y: x + y"} }
HS_PYTHON_CODE_BLOCK_PYTHON_VERSION is set to 3.11. Virtual environment Python version is ignored:
PythonBlock( reference_name='ref_name', code=lambda x, y: x + y, code_input={'x': 0, 'y': 1} ) produces: { "identifier": "PYTHON_3_11_CODE", "reference_name": "ref_name", "input": {"data": {"x": 0, "y": 1}, "code": "lambda x, y: x + y"} }
HS_PYTHON_CODE_BLOCK_PYTHON_VERSION is set to 3.9, but python_version is set to 3.11 in the block instance. Virtual environment Python version is ignored:
PythonBlock( reference_name='ref_name', code=lambda x, y: x + y, code_input={'x': 0, 'y': 1}, python_version=PythonBlock.SupportedPythonBlockPythonVersion.PYTHON_3_11 ) produces: { "identifier": "PYTHON_3_11_CODE", "reference_name": "ref_name", "input": {"data": {"x": 0, "y": 1}, "code": "lambda x, y: x + y"} }
Example usage with a code function:
def code_fn(a_static_input: int, a_dynamic_input: str) -> str: import regex # third party python package return 'found' if regex.search(r'Hello|Hi', 'HelloWorld') else 'not found' function_ccb = PythonBlock( reference_name='example_function_ccb', code=code_fn, code_input={ 'a_static_input': 42, 'a_dynamic_input': some_previous_block.output('path.to.value') }, )
Example usage with a lambda:
lambda_ccb = PythonBlock( reference_name='example_lambda_ccb', code=lambda a_static_input, a_dynamic_input: { 'foo': f'prefix_{a_dynamic_input}', 'bar': 5 + a_static_input }, code_input={ 'a_static_input': 42, 'a_dynamic_input': some_previous_block.output('path.to.value') }, )
- class SupportedPythonBlockPythonVersion(value)
Bases:
str,EnumDescribes which versions of Pyhon can be passed to the python_version argument of PythonCode.
- PYTHON_3_9 = 'PYTHON_CODE'
DEPRECATED from version 40+ due to end-of-life of Python 3.9
- PYTHON_3_11 = 'PYTHON_3_11_CODE'
Available since version 39.1
- PYTHON_3_12 = 'PYTHON_3_12_CODE'
Available since version 41.0
- class flows_sdk.blocks.CodeBlock(code, reference_name=None, code_input=None, input=None, title=None, description=None)
Bases:
BaseCodeBlockDEPRECATED from 34.0.1+ going forward, please use
flows_sdk.blocks.PythonBlockinsteadCode Blocks are a special type of block that can run custom Python code on the Hyperscience Platform. Code will be serialized, then, as part of a flow run, executed on an isolated environment. It will not have access to dependencies outside of basic ones like the Python Standard Library.
Lambda functions are executed in the context of the execution engine itself (less overhead, but cannot be scaled) Code functions are executed in a dedicated container (more overhead, can scale horizontally)
Example usage with a code function:
def code_fn(a_static_input: int, a_dynamic_input: str) -> str: return f'Hello {code_block_input_param}' function_ccb = CodeBlock( reference_name='example_function_ccb', code=code_fn, code_input={ 'a_static_input': 42, 'a_dynamic_input': some_previous_block.output('path.to.value') }, )
Example usage with a lambda:
lambda_ccb = CodeBlock( reference_name='example_lambda_ccb', code=lambda a_static_input, a_dynamic_input: { 'foo': f'prefix_{a_dynamic_input}', 'bar': 5 + a_static_input }, code_input={ 'a_static_input': 42, 'a_dynamic_input': some_previous_block.output('path.to.value') }, )
- IDENTIFIER = 'CUSTOM_CODE'
- class flows_sdk.blocks.Fork(reference_name, branches, title=None, description=None)
Bases:
BlockFork is a system block that is used to schedule other blocks for parallel execution.
While all branches of a Fork will be scheduled for parallel execution, the tasks within a branch itself will be executed serially.
The output of a Fork is a dictionary with key: identifier of the output block from each branch and value: the output from that block
- Parameters:
reference_name (str) – unique identifier on a per-Flow basis
branches (Sequence[Fork.Branch]) – A sequence of branches, that will be scheduled for parallel execution.
title (Optional[str]) – UI-visible title of the block.
description (Optional[str]) – Description of the block. Both useful for documentation purpose and visible to users in the Flow studio.
from typing import Any from uuid import UUID from flows_sdk.blocks import CodeBlock, Fork from flows_sdk.flows import Flow, Manifest from flows_sdk.package_utils import export_flow def entry_point_flow() -> Flow: return example_flow_with_fork() def example_flow_with_fork() -> Flow: ccb_A_1 = CodeBlock( reference_name='ccb_A_1', code=lambda _: {'a': 'response from A 1'}, code_input={'_': None} ) ccb_A_2 = CodeBlock( reference_name='ccb_A_2', code=lambda _: {'a': 'response from A 2'}, code_input={'_': None} ) # Note that both ccb_A_1 and ccb_A_2 will be executed in this branch sequentially, # but because of output=ccb_A_1._reference_name, only it will "ccb_A_1" will have its output # as a key under "fork_output" (check sample output in the comment below) branch_A = Fork.Branch(blocks=[ccb_A_1, ccb_A_2], label='first', output=ccb_A_1._reference_name) ccb_B = CodeBlock( reference_name='ccb_B', code=lambda _: {'b': 'response from B'}, code_input={'_': None} ) branch_B = Fork.Branch(blocks=[ccb_B], label='second', output=ccb_B._reference_name) fork = Fork(reference_name='a_fork', branches=[branch_A, branch_B]) def print_function(fork_output: Any) -> None: print(fork_output) return # { # "ccb_A_1": { # "result": { # "a": "response from A 1" # } # }, # "ccb_B": { # "result": { # "b": "response from B" # } # } # } print_ccb = CodeBlock( reference_name='print_ccb', code=print_function, code_input={'fork_output': fork.output()} ) return Flow( title='Fork sample flow', description='A simple Flow showcasing how a Fork is used', blocks=[fork, print_ccb], owner_email='flows.sdk@hyperscience.com', manifest=Manifest(identifier='fork_example', input=[]), uuid=UUID('3e3ab564-fcf5-41fb-a573-4bc2fd153b6d'), input={}, ) if __name__ == '__main__': export_flow(flow=entry_point_flow())
- class Branch(blocks, label=None, output=None)
Bases:
_BranchA collection of Blocks that will be serially scheduled for execution.
- Parameters:
blocks (Sequence[Block]) – A sequence of Blocks that will be executed as part of that Fork.Branch. Should contain at least one.
label (Optional[str]) – UI-visible text lable of the branch.
output (Optional[str]) – Reference name of the Block which will be used as the output of the entire branch. When not provided, the output of the last block of the branch will be treated as the branch output.
- class flows_sdk.blocks.Routing(decision, branches, reference_name=None, default_branch=None, title=None, description=None)
Bases:
BlockRouting is a system Block that executes only the blocks in one of its branches that meets a condition. Similar in concept to a switch..case or an if/else construction.
- Parameters:
reference_name (
Optional[str]) – [description]decision (
str) – [description]branches (
Sequence[Branch]) – [description]default_branch (
Optional[DefaultBranch]) – [description], defaults to Nonetitle (
Optional[str]) – [description], defaults to Nonedescription (
Optional[str]) – [description], defaults to None
from typing import Any from uuid import UUID from flows_sdk.blocks import CodeBlock, Routing from flows_sdk.flows import Flow, Manifest def entry_point_flow() -> Flow: return example_flow_with_routing() def example_flow_with_routing() -> Flow: decision_ccb = CodeBlock( reference_name='decision_ccb', code=lambda a_char: {'some_field': a_char}, code_input={'a_char': 'A'}, ) ccb_A = CodeBlock( reference_name='ccb_A', code=lambda _: {'a': 'response from A'}, code_input={'_': None} ) branch_A = Routing.Branch(case='A', blocks=[ccb_A], label='first', output=ccb_A._reference_name) ccb_B = CodeBlock( reference_name='ccb_B', code=lambda _: {'b': 'response from B'}, code_input={'_': None} ) default_branch = Routing.DefaultBranch( blocks=[ccb_B], label='default', output=ccb_B._reference_name ) # 'decision' is like a switch..case statement - when a Branch 'case' is matched, it will be # scheduled for execution. If no case matches, a 'default_branch' can be defined as fallback. routing = Routing( reference_name='a_routing', decision=decision_ccb.output('some_field'), branches=[branch_A], default_branch=default_branch, ) def print_function(routing_output: Any) -> None: print(routing_output) return # "routing_output": { # "result": { # "a": "response from A" # } # } print_ccb = CodeBlock( reference_name='print_ccb', code=print_function, code_input={'routing_output': routing.output()}, ) return Flow( title='Routing sample flow', description='A simple Flow showcasing how Routing is used', blocks=[decision_ccb, routing, print_ccb], owner_email='flows.sdk@hyperscience.com', manifest=Manifest(identifier='routing_example', input=[]), uuid=UUID('4e3ab564-fcf5-41fb-a573-4bc2fd153b6d'), input={}, )
- class Branch(case, blocks, label=None, output=None)
Bases:
_Branch[summary]
- Parameters:
case (str) – case that must be matched in order for this branch to be scheduled for execution.
blocks (Sequence[Block]) – sequence of blocks to be executed as part of this branch
label (Optional[str]) – UI-visible text lable of the branch
output (Optional[str]) – Reference name of the Block which will be used as the output of the entire branch. When not provided, the output of the last block of the branch will be treated as the branch output.
- class DefaultBranch(blocks, label=None, output=None)
Bases:
_BranchSame as
flows_sdk.blocks.Routing.Branch, but without a case. DefaultBranch is optionally provided and executed as a fallback when there is no matching case from other branches.
- class flows_sdk.blocks.IOBlock(identifier, enabled, reference_name=None, input=None, title=None, description=None)
Bases:
BlockA Block that has the additional boolean property enabled. Used for Triggers and Outputs where enabled can be triggered via the Flow Studio UI and is considered during processing (e.g. only enabled Triggers can initiate Flow execution).
See
flows_sdk.blocks.Blockfor description of the inherited parameters.- Parameters:
enabled (bool) – on-off state of the Block. Visualized as a checkbox and taken into account during processing.
- class flows_sdk.blocks.Outputs(role_filter, input_template, blocks, reference_name=None, title=None, description=None)
Bases:
BlockOutputs is a special block-section meant to provide an easy way for users to configure Flow output connections through the UI. They contain a list of output blocks, that can optionally be filtered by role and define an input template that will wire these blocks’ inputs automatically after the user adds them.
- Parameters:
reference_name (
Optional[str]) – unique identifier on a per-Flow basis, used to identify the concrete block within a Flow (e.g., in order to reference the outputs of a concrete block)role_filter (
List[str]) – Serves as an instruction to the UI for what blocks are allowed in this output section, since not all output blocks will be suitable for all flows. UI will allow adding only blocks that have all listed roles. If empty, blocks with any role will be allowed.input_template (
Dict[str,Any]) – Used by the UI to automatically pre-populate the input of newly added blocks. Thus the Flow designer can define the wiring of output blocks to the results from previous blocks in the Flow, while allowing the user to add or remove output blocks via the UI.blocks (
Sequence[IOBlock]) – List of output IOBlocks for sending results to external systems. Can be empty, since the outputs within an Outputs section are editable in Flow studio.title (
Optional[str]) – UI-visible title of the block.description (
Optional[str]) – Description of the block. Both useful for documentation purpose and visible to users in the Flow studio.
- class flows_sdk.blocks.Foreach(items, template, reference_name, title=None, description=None)
Bases:
BlockAvailable in v35 and later.
Foreach is a system block that can be used to run a given task for each item in a collection. The task is represented by a block and the collection is dynamically generated at runtime - can be a flow input or the output of a previous block. The block that will run for each item in the collection is called a “template” and supports special syntax for referencing the basic foreach loop concepts:
${foreach_reference_name.item}- to access the current item. Syntax like ${foreach_reference_name.item.nested_prop} is also supported.${foreach_reference_name.index}- to access the index of the current item, 0-based
At runtime Foreach dynamically generates blocks by applying the template to each item in the collection. The generated blocks are executed in parallel. The output of the Foreach block is a list that contains the outputs of the dynamically created blocks in the same order as the input collection.
- Parameters:
items (
str) – reference to the list of items to which the template will be appliedtemplate (
Block) – the block to run for each item in the provided collectionreference_name (
str) – unique identifier of the block in the flow. Note that unlike in other blocks here the reference_name is not optional as it is needed to refer to the items of the collection in the templatetitle (
Optional[str]) – UI-visible title of the block.description (
Optional[str]) – Description of the block. Both useful for documentation purposes and visible to users in the Flow studio.
import sys from typing import List from uuid import UUID from flows_sdk.blocks import CodeBlock, Foreach from flows_sdk.flows import Flow, Manifest from flows_sdk.package_utils import export_flow def entry_point_flow() -> Flow: return example_flow_with_foreach() def example_flow_with_foreach() -> Flow: def _create_items() -> List[int]: return [1, 2, 3, 4] create_items = CodeBlock(reference_name='create_items', code=_create_items, code_input={}) def multiply_by_2(n: int) -> int: return n * 2 foreach = Foreach( reference_name='multiply_by_2', items=create_items.output(), template=CodeBlock( reference_name='multiply_ccb_${multiply_by_2.index}', code=multiply_by_2, code_input={'n': '${multiply_by_2.item}'}, ), ) def sum_numbers(multiplied_numbers: list) -> int: # the outputs of the code blocks are wrapped in a dict like {'result': <actual_number>} return sum([n['result'] for n in multiplied_numbers]) use_foreach_output = CodeBlock( reference_name='sum_numbers', code=sum_numbers, code_input={'multiplied_numbers': foreach.output()}, ) return Flow( title='Foreach sample flow', description='A simple Flow showcasing how FOREACH is used', blocks=[create_items, foreach, use_foreach_output], owner_email='flows.sdk@hyperscience.com', manifest=Manifest(identifier='FOREACH_EXAMPLE', input=[]), uuid=UUID('a1edebd9-e96f-4c10-beeb-6cce3e92d4f1'), input={}, ) if __name__ == '__main__': export_filename = None if len(sys.argv) > 1: export_filename = sys.argv[1] export_flow(flow=entry_point_flow(), filename=export_filename)
- output(key=None)
Used to reference the output of a block that has already been executed. For example, if we have a Flow with two blocks, the second can reference the output of the first as part of its inputs.
- Parameters:
key (Optional[str]) – When not provided, the entire output of the referenced block will be passed along. When provided, will pass a concrete key from the output (e.g. for an output like
{"a": 42}, callingoutput()will pass it as a dictionary, while callingoutput("a")will pass42.)- Returns:
a string-formatted reference that will be unpacked to a value during runtime.
- Return type:
str
For example:
a = Block(...) b = Block( ..., input = { 'foo': a.output('bar') } )
flows.py
- pydantic model flows_sdk.flows.Parameter
Bases:
_BaseModelDefines an input parameter of a block or a flow.
- Fields:
-
field dependencies:
Optional[List[Dependency]] = None Internal mechanism for describing dependencies between fields (e.g. show A when B is checked, hide A when B is unchecked)
-
field description:
Optional[str] = None UI-visible description of the field
-
field json_schema:
Optional[Dict[str,Any]] = None (alias 'schema') Defines a format for the field using the JSON Schema specification (https://json-schema.org/understanding-json-schema/). Field values will be validated against this format when a flow is imported or edited.
-
field name:
str[Required] Must be a valid Python identifier
-
field optional:
bool= False True when the field can be omitted, False when it is mandatory. The default value is False, i.e. if the optional flag is not specified, the field will be considered mandatory.
-
field secret:
Optional[bool] = None UI-hint that the field should be presented as a secret (hidden symbols) rather than plain text.
-
field title:
Optional[str] = None UI-visible representation of the field name
-
field type:
str[Required] Json-schema-like type (e.g. string, integer, number, array, object…) Between Hyperscience platform versions there are also extensions like:
Percentage (number between 0 and 1)
UUID (string in UUID format or null)
MultilineText (string, but represented as multiline text box in Flow studio)
Depending on the Hyperscience version, other supported types may also exist, some of which allow for specific rendering in UI.
-
field type_spec:
Optional[Dict[str,Any]] = None An optional object property that further specifies (or “specializes”) the type, in ways that cannot be achieved via the schema property. Its exact format is specific to the specific type used. If specified must conform to whatever the type_spec format specific to the chosen type is.
File input flow that uses type_spec
This flow uses type_spec to limit the types of files that can be selected for the file input.
from uuid import UUID from flows_sdk.blocks import CodeBlock from flows_sdk.flows import Flow, Manifest, Parameter from flows_sdk.package_utils import export_flow from flows_sdk.types import HsBlockInstance from flows_sdk.utils import workflow_input FILE_INPUT_FLOW_IDENTIFIER = 'FILE_INPUT_SHOWCASE' FILE_INPUT_FLOW_UUID = UUID('2869449d-db9e-485b-b285-f954346793c6') class FlowInputs: FILE = 'file' def entry_point_flow() -> Flow: return file_input_showcase_flow() def file_input_showcase_flow() -> Flow: def _read_and_log_file(file_uuid: str, _hs_block_instance: HsBlockInstance) -> str: if not file_uuid: _hs_block_instance.log('No file configured') return '' blob = _hs_block_instance.fetch_blob(file_uuid) file_text = blob.content.decode(encoding='utf-8') _hs_block_instance.log(file_text) return file_text read_and_log_file = CodeBlock( reference_name='read_and_log_file', code=_read_and_log_file, code_input={'file_uuid': workflow_input(FlowInputs.FILE)}, ) return Flow( title='Flow with a file input', description='Accepts a text file as an input and logs and outputs its contents', blocks=[read_and_log_file], owner_email='flows.sdk@hyperscience.com', manifest=Manifest( identifier=FILE_INPUT_FLOW_IDENTIFIER, input=[ Parameter( name=FlowInputs.FILE, title='File to read', type='File', # restricts the type of file that can be selected type_spec={'allowed_extensions': '.txt'}, optional=True, ) ], ), uuid=FILE_INPUT_FLOW_UUID, input={FlowInputs.FILE: 'some_text.txt'}, ) if __name__ == '__main__': export_flow(flow=entry_point_flow())
-
field ui:
Optional[Dict[str,Any]] = None Presentation-related customizations for the field
-
field value:
Any= None Optional default value of the field, used when its value is not specified explicitly in the inputs
- pydantic model flows_sdk.flows.InputDefinition
Bases:
_BaseModelDeclaratively defines what parameters are expected, usually part of a Manifest.
-
field ui:
Optional[Dict[str,Any]] = None Presentation-related customizations for how fields are grouped together. ui[‘groups’] defines how fields are grouped together in the UI and specifies the group titles. groups are optional - if omitted, every input field is listed in the “default” group. If any fields are not included in any group, then they are shown as part of the “default” group of non-nested fields.
example:
ui: { groups: [ { title: 'Group 1', fields: [ 'layout_release_uuid', 'policy', ], }, { title: 'Group 2', fields: ['accuracy'], }, ] }
-
field ui:
- pydantic model flows_sdk.flows.Manifest
Bases:
InputDefinitionDescribes how the Flow studio should present the Flow/Block. The parameters are displayed in the Flow studio and can be futher customized into sections via. the ui section.
Inputs are used both for visualization and for validation - for example, in the
flows_sdk.flows.Flowmanifest.input, if a string is passed for a parameter defined as number in the manifest, the user will be prompted toHere is an example of how the manifest is visualized on the Flow level with
flows_sdk.flows.Parametergroupped under Classification and Identification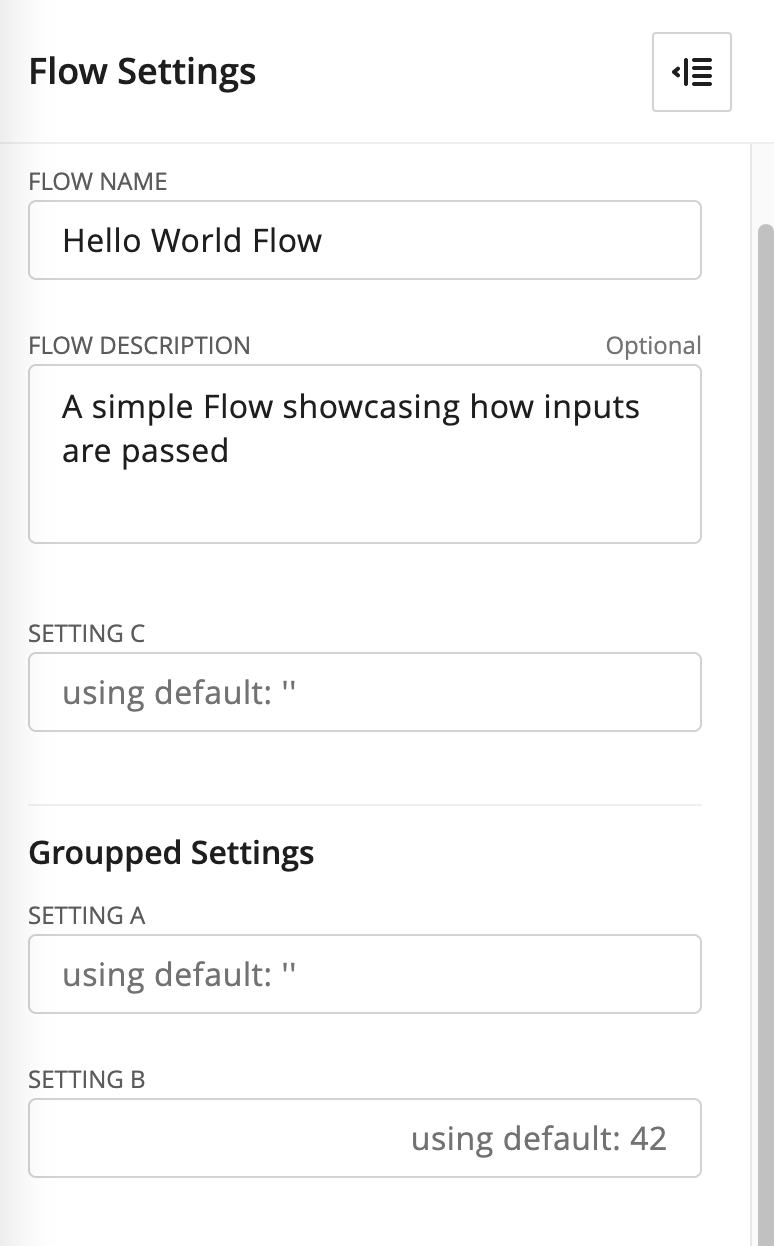
example:
Manifest( identifier='CUSTOM_FLOW', input=[ Parameter( name='setting_a', type='string', title='Setting A', value='' ), Parameter( name='setting_b', type='number', title='Setting B', value=42 ), Parameter( name='setting_c', type='string', title='Setting C', value='' ), ], ui={ 'groups': [ { 'title': 'Groupped Settings', 'fields': [ 'setting_a', 'setting_b', ], }, ] } )
- Fields:
-
field enable_overrides:
Optional[bool] = None UI representation of overrides if present. This requires additional API calls and should generally be set to True only when overrides are defined Advanced functionality, contact Hyperscience if you think you need it!
-
field identifier:
str[Required] Globally-unique identifier of the block/flow. By convention - all capital snake-case witn an optional numeric suffix (e.g.,
HELLO_FLOW_2)
-
field output:
Optional[List[Parameter]] = [] Documents the outputs of the block/flow. For the time being, used for documentation purposes only.
-
field roles:
List[str] = [] Allows for “tagging” blocks/flows, used by internal features.
- pydantic model flows_sdk.flows.Flow
Bases:
_BaseModelFlow is the top-level construct describing the type and order of various components.
Sample usage:
Flow( title='Flow title', # UI visible and editable title description='Flow description' # UI visible and editable description blocks=[ccb], # sequence of blocks in order owner_email='flows.sdk@hyperscience.com', manifest=Manifest(identifier='HELLO_FLOW', input=[hello_input_param]), uuid=UUID('2e3ab564-fcf5-41fb-a573-4bc2fd153b6d'), input={'hello_input': 'World'}, )
- Config:
arbitrary_types_allowed: bool = True
- Fields:
-
field blocks:
Sequence[Block] = [] Sequence of Blocks to be scheduled for execution when the Flow is triggered.
-
field description:
Optional[str] = None User-editable description of what the Flow is used for.
-
field error_handling:
Optional[ErrorHandling] = None Error handling policies for the flow.
-
field input:
Dict[str,Any] = {} Key-value pairs for top-level inputs of the flow. Their types / UI representations are part of the Manifest.
-
field output:
Optional[Dict[str,str]] = None
-
field owner_email:
str[Required] An email address where the creator of the Flow can be reached. This field is purely informative metadata, it does not control any permissions or behaviours in the system. The intended use is for the flow developer to define it in the Flows SDK-based definition of the flow. It is read-only in the UI because business users will mostly be using this for information purposes and will not usually need to change it. If necessary, they may still change this by exporting, editing the json of the flow, and reimporting.
-
field title:
str[Required] User-visible and editable title, does not have to be unique.
-
field triggers:
Optional[Triggers] = None Trigger blocks that initiate the Flow.
-
field uuid:
UUID= UUID('00000000-0000-0000-0000-000000000000') Unique identifier of the Flow. If not provided, one will be deterministically generated based on the value of manifest.identifier. Note that if manually setting the uuid, a new one should be used every time manifest.identifier changes.
-
field variables:
Optional[Dict[str,Any]] = None
- classmethod generate_uuid_when_not_provided(values)
Generate a deterministic UUID based on manifest.identifier if one is not provided. We use _ZERO_UUID as an anchor value to ensure that the type of uuid is kept as UUID instead of Optional[UUID], as some pieces of code might rely on the value being a valid UUID instead of Null that gets rendered to a valid UUID.
- Return type:
Dict[str,Any]
types.py
This module contains types that can be useful for writing flows but are not part of the flow’s topology.
Available in v35 and later.
- class flows_sdk.types.StoreBlobRequest(name, content)
Bases:
objectEncapsulates the request parameters for storing a blob.
-
name:
str Name that will be associated with the blob.
-
content:
bytes Blob content in bytes.
-
name:
- class flows_sdk.types.StoreBlobResponse(uuid, name)
Bases:
objectThe result of storing a blob. Contains data that can be used to retrieve the blob.
-
uuid:
str Unique identifier of the created blob.
-
name:
str Name associated with the blob.
-
uuid:
- class flows_sdk.types.Blob(content)
Bases:
objectThe result of fetching a blob from the object store.
-
content:
bytes The content of the blob in bytes.
-
content:
- class flows_sdk.types.HsTask(task_id, flow_run_id, correlation_id, task_name, reference_name)
Bases:
objectA task in the flow engine runtime - contains task and flow metadata.
Available in v35 and later.
-
task_id:
str Unique identifier of the task withing the system
-
flow_run_id:
str Unique identifier of the flow run withing the system
-
correlation_id:
str A string that gets passed from parent to child flow runs and can be used to identify flow runs that belong to the same execution graph
-
task_name:
str The name of the block that runs the task, e.g. PYTHON_CODE
-
reference_name:
str The unique identifier of the task in the flow definition
-
task_id:
- class flows_sdk.types.Measurement(*args, **kwargs)
Bases:
objectThe datum or numerical value associated with a metric, described over the respective dimensions. AKA Fact in the OLAP world.
Measurements do not have uniqueness properties. Two measurements with the exact same values will not be considered duplicate, but rather different measurements taken at the same time, for the same metric, with the same value and dimensions.
Available in V41 and later.
-
name:
str Name is the machine identifier for a metric. Names cannot be blank and, alongside namespace, represent the identifier of a metric.
-
namespace:
str Namespace represents the context under which the metric is used. This property avoids conflicts between metrics with the same name, used in different contexts. Similar to the name field, a namespace cannot be blank.
-
time:
datetime The ‘time’ field refers to the “occurrence time” where the measurement was taken. In event-driven architecture (EDA) this is usually referred to as “event time”, and just like in EDA, this has no relation to the real time, i.e., the time at which the event/measurement is processed by the analytics system. This datetime field must be timezone-aware.
-
dimensions:
dict[str,str] Dimensions provide the “who, what, where, when, why, and how” context surrounding a measurement. They contain the attributes which characterize the measurement, which, at the analytical level, can be used to filter and/or group measurements.
-
value:
float The datum associated with a metric, described over the respective dimensions. AKA Fact in the OLAP world.
-
name:
- class flows_sdk.types.HsBlockInstance
Bases:
ABCProvides an interface for the base block APIs in code blocks.
Available in v35 and later.
- abstract store_blob(blob)
Stores a blob in the object store. For more information see store_blobs.
- Parameters:
blob (
StoreBlobRequest) – The binary object to store.- Returns:
A response object that contains the blob’s unique identifier.
- Return type:
- abstract store_blobs(blobs)
Stores a list of blobs in the object store. The blobs will be associated with the flow run where this code gets executed. When this flow run is deleted the blobs will be deleted as well.
- Parameters:
blobs (
Iterable[StoreBlobRequest]) – List of blobs to store.- Returns:
A list of response objects that contain the blobs’ unique identifiers.
- Return type:
List[StoreBlobResponse]
- abstract fetch_blob(blob_reference)
Retrieves the contents for the provided blob reference string.
- Parameters:
blob_reference (
str) – The unique identifier of the blob to be fetched.- Returns:
The blob’s content. If no blob with the provided reference exists, an exception will be raised.
- Return type:
- abstract log(msg, level=LogLevel.INFO)
Logs a message at the given log level both to the standard out/err stream and to the flow execution context, making it available in the Logs tab of the View Flow Execution UI. Prepends meta information that makes the logs easier to trace (e.g. by correlation id)
- Parameters:
msg (
str) – The message to log.level (
LogLevel) – The log level to use. Defaults to INFO.
- Return type:
None
- hs_request(method, app_endpoint, **kwargs)
Available in v40.2 and later.
Makes an authenticated HTTP request to the Hyperscience platform. This method will automatically take care of prepending the base url and will include the appropriate authentication headers with the request.
Mandatory parameters:
- Parameters:
method (
str) – HTTP method to use, e.g. ‘GET’, ‘POST’, etc.app_endpoint (
str) – relative url, beginning with a forward slash, to an HTTP endpoint served by the Hyperscience platform. For reference on the available endpoints, check out https://docs.hyperscience.com/. Absolute URLs that include a hostname are allowed only if the flow has received them as part of the response of a previous API request that the flow has made. Do not hardcode the hostname of the Hyperscience instance in your flow definitions as they will not work when you run the flows on another instance, or if the hostname changes.
Optional Parameters:
- Parameters:
kwargs (
Dict[Any,Any]) – Additional keyword arguments to pass to the request call - the requests library is used under the hood. E.g. POST requests probably need a body passed via the data or json argument. See https://requests.readthedocs.io/en/latest/api/#requests.request.- Return type:
Any- Returns:
A requests.Response object
- hs_get(app_endpoint, **kwargs)
Available in v40.2 and later.
Makes an authenticated GET request to the Hyperscience platform. See docs for HsBlockInstance.hs_request above.
- Return type:
Any
- hs_post(app_endpoint, **kwargs)
Available in v40.2 and later.
Makes an authenticated POST request to the Hyperscience platform. See docs for HsBlockInstance.hs_request above.
- Return type:
Any
- abstract publish_measurements(measurements)
Available in v41 and later.
Publishes measurements to the Hyperscience analytics system.
Mandatory parameters:
- Parameters:
measurements (
list[Measurement]) – The provided measurements are persisted in the system, and are eventually available in Hyperscience reports.- Return type:
None
- class flows_sdk.types.CompatibilitySpec(filter_roles=None, filter_schema=None, label=None)
Bases:
objectAvailable in v38 and later.
Provides a definition of the compatibility spec used in blocks. The spec allows to change the identifier of a block or a flow to the identifier of a block that corresponds to the spec.
-
filter_roles:
Optional[List[str]] = None Takes a list of strings that represent flow or block roles and allows the UI to filter by them
-
filter_schema:
Optional[Dict[str,Any]] = None Represents a JSON schema, that allows for more intricate filtering.
-
label:
Optional[str] = None Represents the UI label in FlowStudio
- static compatibility_spec_dict_factory(data)
- Return type:
Dict[str,Any]
-
filter_roles:
error_handling.py
This module contains classes related to flow error handling. Currently, the error handling framework includes:
Automatic retries of block errors. Available in R36+. This feature allows configuring an error retry policy on the flow or block level. If a block has an error retry policy defined on itself or on its parent flow and its execution results in an error a new block with the same input parameters will get scheduled by the flow engine after a time interval, calculated based on the effective error retry policy of the failed block.
On error flows. Available in R38+. This feature allows users to configure a flow to run in case a flow run fails. Each failed flow run will trigger its own on error flow which will receive the UUID for the failed flow run as input under the input key “failed_run_uuid”. The on error flow is invoked only on terminal failure, errors that will be retried by the block error retry policy will not trigger it. Currently, can be configured only in a flow level error handling section.
- class flows_sdk.error_handling.RetryMethod(value)
Bases:
str,EnumRetry methods for handling block errors in flows. Each method has its own formula for calculating the time between a failure and the next retry attempt. Check each enum member for the specific formula. When calculating your error retry policy values keep in mind that what you get as a result using the formulas below is the minimum time between retry attempts, blocks may take additional time to actually run the work.
Available in v36 and later.
- FIXED = 'FIXED'
Each retry runs after retry_interval_seconds seconds.
- LINEAR_BACKOFF = 'LINEAR_BACKOFF'
Next retry is scheduled after retry_interval_seconds * attempt_number seconds.
- EXPONENTIAL_BACKOFF = 'EXPONENTIAL_BACKOFF'
Next retry is scheduled after retry_interval_seconds * 2 ^ (attempt_number - 1) seconds. This means that the first attempt runs after retry_interval_seconds seconds, the second one after 2 * retry_interval_seconds, then 4 * retry_interval_seconds, etc.
- NO_RETRY = 'NO_RETRY'
Not retried.
- class flows_sdk.error_handling.ErrorRetryPolicy(*args, **kwargs)
Bases:
objectBase class for all error retry policies.
-
method:
RetryMethod The algorithm that should be applied when calculating the delay between each retry attempt.
-
method:
- class flows_sdk.error_handling.SimpleErrorRetryPolicy(*args, **kwargs)
Bases:
ErrorRetryPolicyBase class for simple error retry policies that are defined by their method, retry count and a retry interval in seconds.
Available in v36 and later.
-
retry_count:
int How many time a failed block should be retried. This means that if retry_count=3 the block can run up to 4 times within a single flow run - 1 original run + 3 retries.
-
retry_interval_seconds:
float The base interval to use when calculating the delay between each retry attempt. Will result in different delays depending on the selected retry method.
-
retry_count:
- class flows_sdk.error_handling.NoRetryErrorRetryPolicy(*args, **kwargs)
Bases:
ErrorRetryPolicyNo retry, fail on the first unhandled error during execution. This policy can be used to prevent retries for specific blocks in flows that define an error retry policy.
Available in v36 and later.
-
method:
RetryMethod= 'NO_RETRY' The algorithm that should be applied when calculating the delay between each retry attempt.
-
method:
- class flows_sdk.error_handling.OnErrorFlow(*args, **kwargs)
Bases:
objectSpecifies the details of the flow that should run in case a flow run fails. Note that the OnErrorFlow would be called only in case of terminal failure, failures that will be retried will not trigger it.
Check out the example for more details - Submission-aware OnError flow
Available since v38.
-
identifier:
str The identifier of the flow that should be called on error.
-
identifier:
- class flows_sdk.error_handling.ErrorHandling(*args, **kwargs)
Bases:
objectContainer for error handling related concepts for blocks and flows.
Available in v36 and later.
-
block_error_retry_policy:
Union[SimpleErrorRetryPolicy,NoRetryErrorRetryPolicy,None] = None This error retry policy will be applied to all blocks in the flow. Individual blocks can override this using the same class.
Example
from uuid import UUID from flows_sdk.blocks import CodeBlock from flows_sdk.error_handling import ( ErrorHandling, NoRetryErrorRetryPolicy, RetryMethod, SimpleErrorRetryPolicy, ) from flows_sdk.flows import Flow, Manifest, Parameter from flows_sdk.package_utils import export_flow from flows_sdk.utils import workflow_input BLOCK_RETRIES_FLOW_IDENTIFIER = 'BLOCK_RETRIES_SHOWCASE' BLOCK_RETRIES_FLOW_UUID = UUID('59ebf286-686c-4df0-9b5f-f949607780ad') class FlowInputs: N_SECONDS = 'n_seconds' def entry_point_flow() -> Flow: return block_error_retries_showcase_flow() def block_error_retries_showcase_flow() -> Flow: def _create_start_date() -> str: from datetime import datetime return datetime.now().isoformat() create_start_date = CodeBlock( reference_name='create_start_date', code=_create_start_date, code_input={}, ).with_error_handling( ErrorHandling( # overrides the flow level retry policy for this block with NO_RETRY block_error_retry_policy=NoRetryErrorRetryPolicy() ) ) def _fail_until_n_seconds_later(start_date: str, n_seconds: int) -> None: from datetime import datetime, timedelta if datetime.now() < datetime.fromisoformat(start_date) + timedelta(seconds=n_seconds): raise Exception('Too early to complete!') fail_until_n_seconds_later = CodeBlock( reference_name='fail_until_n_seconds_later', code=_fail_until_n_seconds_later, code_input={ 'start_date': create_start_date.output(), 'n_seconds': workflow_input(FlowInputs.N_SECONDS), }, ) return Flow( title='Block retries sample flow', description='Sample flow with a retry policy', blocks=[create_start_date, fail_until_n_seconds_later], owner_email='flows.sdk@hyperscience.com', manifest=Manifest( identifier=BLOCK_RETRIES_FLOW_IDENTIFIER, input=[ Parameter( name=FlowInputs.N_SECONDS, title='Fail for this may seconds', type='integer', optional=False, ) ], ), uuid=BLOCK_RETRIES_FLOW_UUID, input={FlowInputs.N_SECONDS: 30}, error_handling=ErrorHandling( # retry up to 20 times with 5 seconds between attempts # will be applied to all blocks in the flow block_error_retry_policy=SimpleErrorRetryPolicy( method=RetryMethod.FIXED, retry_count=20, retry_interval_seconds=5 ) ), ) if __name__ == '__main__': export_flow(flow=entry_point_flow())
-
on_error_flow:
Optional[OnErrorFlow] = None Specification for a flow that should run on error. Can be used only for error handling attached on the flow level.
Available since v38.
-
block_error_retry_policy: